Three Short Reliability Stories
By Robert Shaw
10.11.19
By Robert C. Shaw, Jr., PhD, Vice President of Examinations, National Board for Respiratory Care
Within a recent Credentialing Insights article, “Exploring the Psychometric Concept of Reliability,” Timothy Muckle, PhD, did a nice job of alerting readers to concepts and tools that can help them better understand reliability indices that are documented when test results are summarized. Timothy emphasized the link between the quantity of items on a test (K) and the subsequent coefficient alpha or KR20 indices observed after a group has taken a test. The reliability index and K are directly related so more K must be better, right? Two of the three stories will indicate that this principle is not universal. Timothy also discussed points about measurement error, uncertainty this error creates in observed scores and he defined a candidate’s true score, which are considered in these three stories.
A psychometrician scrutinizes the cluster of information that includes K, reliability and decision consistency (DC) to get a sense about a program’s strengths and weaknesses plus what might be improvement opportunities. The level of detail in these three stories may surprise some readers since each is inferred from only three pieces of information. For the purpose of simplifying each story, assume each test contains multiple-choice items that are dichotomously scored and independent of one another. Timothy told us reliability will be expressed as a KR20 value in such circumstances.
The Quick and Dirty
A program reports the following information about its last test administration: K = 60, KR20 = .81, DC = .82. The following can be inferred:
- The organization that launched the program wanted a short test administration time above all else and may not have thought about whether the breadth of content coverage or measurement accuracy would be enough.
- For a 60-item test, a KR20 of .81 is better than the worst case; however, there remains a lot of measurement error in the set of scores.
- Despite there being lots of measurement error, the organization is not giving candidates with scores near the cut score much benefit of uncertainty about whether their true abilities can be considered competent. (Timothy told us each candidate has a score we can see that may be influenced by error plus a true score we would see after error was removed.)
If decision-makers were open to improvements, then this psychometrician would likely advise them to increase K. While small KR20 increases could be expected by increasing the quality of items, such a quality improvement strategy will take years to exert an effect. In the meantime, legitimate uncertainty will remain about the accuracy of decisions for about 19% of each group. If this percentage could be reduced to single digits, then a notable improvement would have been made.
The Spearman-Brown prophecy tool described by Timothy becomes useful to a psychometrician in this scenario. While assuming item quality (difficulty and discrimination) remain the same, incrementally increased test lengths can be modeled. The point at which KR20 can be expected to rise to a sufficiently high level can be estimated. Moving from left to right across Figure 1 supports a recommendation to increase test length to at least 100 while lengths of 120 or 140 would more likely yield the kind of incremental increase that would make the change worthwhile. As Timothy said, the KR20 curve flattens as K increases. Illustrating this point, one should expect a limited KR20 increase between Ks of 140 and 240 while the KR20 increase between 60 and 160 is dramatic.
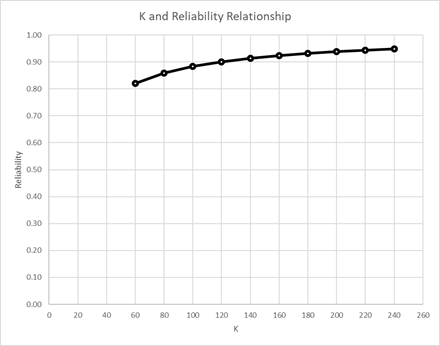
Figure 1
A test with a larger K and administration time are the best short-term interventions. When the new test is first deployed, the passing standard will be revisited so an opportunity to reconsider the location of the cut score will open. Considering the DC value while choosing the new cut score creates an opportunity to treat some candidates with greater fairness. The benefit for the program is it can document a larger value describing the proportion of candidates who experienced a practically certain pass or fail result.
If one could observe a K of 120, KR20 of .89 and DC of .92 after K was doubled, then one would confirm that the decision-makers had made thoughtful changes. The increment between a KR20 of.89 and a DC of .92 is typically created by choosing a cut score slightly lower than otherwise would be selected. Candidates with scores at the cut score plus those a few points above would fail compared to the higher cut score that would have been selected before DC is considered. These candidates whose scores are within the margin of error of the higher potential cut score are more fairly treated as a result.
The KR20 of .89 is a bit lower than Figure 1 predicted for a K of 120. However, it is also likely that the influx of new items needed to increase test length will be of slightly lower quality than those that had persisted in the bank. It is realistic to expect a KR20 slightly less than modeled when new items are added.
The Efficient
A program reports the following information about its last test administration: K = 130, KR20 = .91, DC = .93. The following can be inferred:
- The organization that launched this program wanted solid measurement values while being willing to implement the test administration time that was necessary to achieve those values.
- For a 130-item test, a KR20 of .91 is pretty good. The program can continue to pursue quality improvements over time that may eventually yield a higher KR20.
- Despite there being only a low level of measurement error, the organization is giving some candidates at and just above the cut score the benefit of uncertainty about their true achievement levels.
When the DC estimate is .93, about 7% of the candidate group could experience the other pass or fail outcome on another attempt while assuming they learned nothing new from taking the test the first time. Think of the 7% as the small group in the middle of the test score distribution who have scores within the margin of error around the cut score. The other 93% of candidates have scores located above and below this middle group while the same pass or fail outcome is expected for them with a theoretic second attempt.
I would recommend leaving the test length where it is. Good things are happening on the KR20 front and candidates within the margin of error receive fair treatment.
If another program reported a K close to or equal to 130 plus a KR20 of .91 with a DC of .91, then I would infer that the fail rate is higher than observed in the first program showing respective values of .91 and .93. Another viable inference could be that the second program with a KR20 of .91 and a DC of .91 has earned the luxury of placing its passing standard in a high location. The luxury is typically earned over time by producing and accumulating high quality test items with strong statistics. When a psychometrician encourages a group to leave an item alone because its statistics are strong, he or she is trying to allow the program this luxury.
The Overkill
A program reports the following information about its last test administration: K = 250, KR20 = .92, DC = .92. The following can be inferred:
- The organization that launched this program wanted a rigorous assessment of competence and concluded that high K plus a long test administration meant more rigor.
- For a 250-item test, a KR20 of .92 is good but likely less than optimal. The mass quantity of items accounts for a large portion of the observed KR20 level.
- There is a low level of measurement error; however, the organization is not giving candidates just below the cut score much benefit of uncertainty about their true achievement levels.
I would recommend enhancing the typical item challenge level plus a simultaneous reduction in the test length. Test administration time is not described, but the only way to cram 250 item responses into a half-day session is to limit items to prompts about memorized facts. A KR20 of .92 does not excuse this overkill scenario. Tests like these take more time to administer than tests with fewer items, which means test center seat time costs more than it otherwise would. Longer tests consume more organizational resources to produce a steady stream of new items. Assuming the organization charges each candidate a fee that just offsets test production and administration costs, candidates pay more than they would pay for a shorter, better test.
Expanding on what “better” means, the first concept I want convey is that rigor can be created by presenting a more challenging, more complex mix of items on a test even when there are fewer items. Asking candidates to regurgitate 250 memorized facts is not automatically better than asking them to apply their fact-based understanding to fewer items in a well-designed sample of scenarios that they think through to solve.
The Spearman-Brown prophecy is a useful tool again to give concrete direction about how much shorter the better test could be. The goal is to shorten the test without an important reduction in measurement accuracy. Starting from the far right side of Figure 2 this time, the KR20 threshold of .90 is crossed at 190 items. Such a change would peel off about an hour of test administration time while retaining the fact-based items. However, if characteristics of most items were simultaneously made more challenging such that more cognitive processing was prompted, then a test containing 160 or 150 items might be deployed. Potentially, a 90-minute reduction in test administration time could be attained without really losing measurement accuracy.
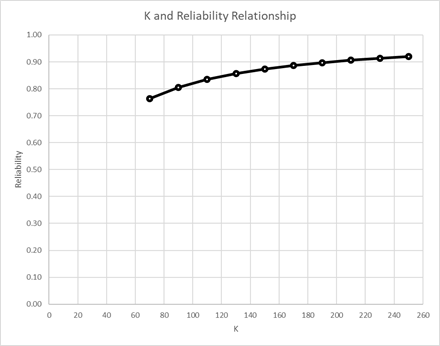
Figure 2
Lastly comes the choice between giving candidates with scores inside the range of potential cut scores the benefit of uncertainty about their true scores or setting a higher standard because it has been earned by a KR20 of at least .90. The choice between these two legitimate outcomes contributes to the reason why it is said that the location of a cut score is an organization’s policy decision.
Summary
These stories are intended to help decision-makers more fully understand one psychometrician’s thought process when testing programs are evaluated. A lot can be inferred from only the K, KR20 and DC values. After adding information about the typical quantity of candidates, test administration time and the test design specifications, each story becomes more nearly complete.
There is a word of caution to add. A reader who leaves this article having concluded that a 130-item test is optimal will often be incorrect. A program’s optimal K depends on several characteristics. The potential permutations quickly grow while including the typical range of candidates’ abilities, the mix of challenge levels created by items, the mix of topics and cognitive demand of these items, the quality of these items in differentiating among candidates’ abilities and the location of the cut score within the distribution of test scores. Each program creates its own story.
Related Article
Exploring the Psychometric Concept of Reliability by Timothy Muckle, PhD